In development · Personal use
It is an AI-powered read-it-later service built end-to-end with Next.js 16 App Router,
Prisma ORM, and Auth.js. Save articles, highlights, and links from anywhere — then let
an AI layer surface what actually matters across your reading history.
No more forgotten bookmarks. No more overflowing reading lists with zero recall.
It connects the dots across everything you've saved and makes your content
library useful again.
Saving content is easy. Finding it again isn't.
Most knowledge workers have the same problem: they save articles, threads, and links
constantly — but almost never go back to them. The content sits in a Pocket or
Instapaper graveyard, never to be seen again.
Existing read-it-later tools treat saving and reading as two separate, disconnected acts.
There's no layer that connects what you've saved with what you're currently working on
or thinking about. The library grows, but it never gets smarter.
The insight: saving is only useful if you can reliably rediscover content at the
moment it becomes relevant. That requires an AI layer — not just search.
A read-it-later service with a memory
The app adds a RAG (Retrieval-Augmented Generation) layer on top of a standard
content library. When you save an article, it's parsed, chunked, and embedded into a
vector store (Pinecone). When you ask a question or describe what you're working on,
the AI retrieves semantically relevant content from your personal library and surfaces it.
The result: your saved content stops being an archive and starts being an active
knowledge base that you can query in plain language.
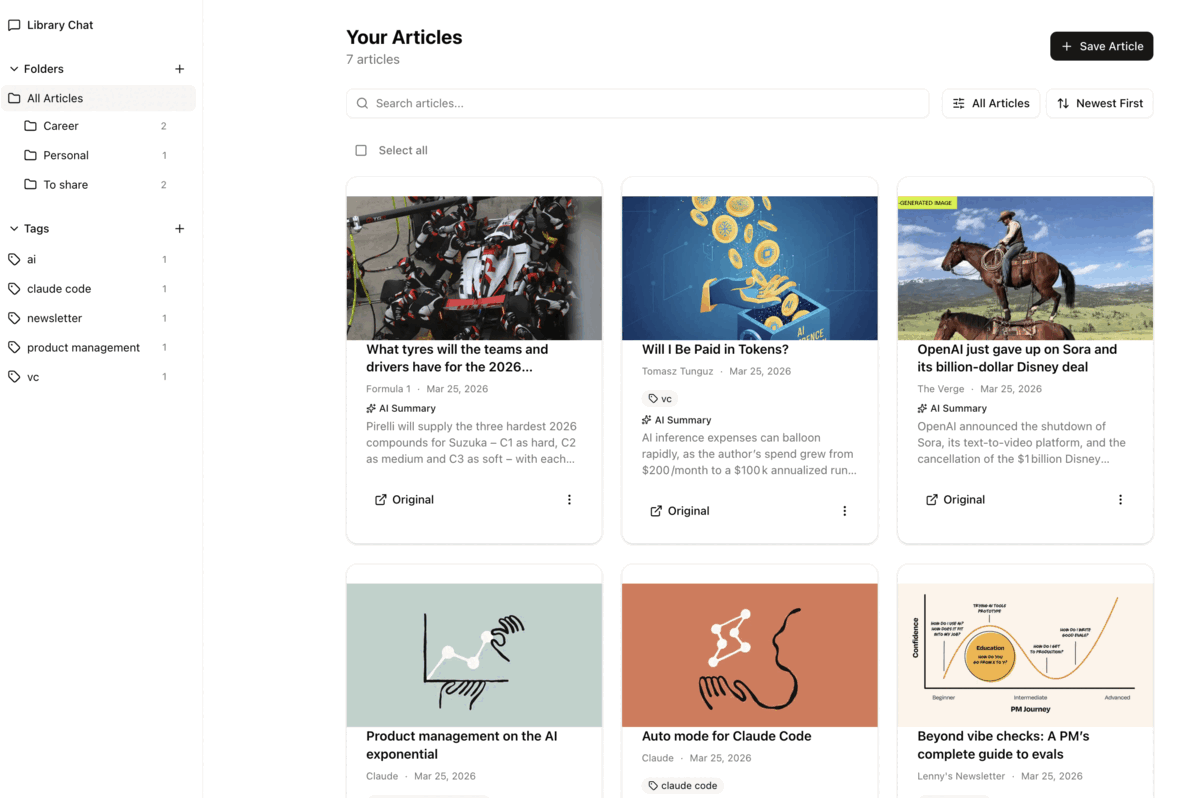
The app in action
The main interface lets you save, browse, and query your personal content library using natural language — powered by RAG over your own saved articles.
Save once, surface when it matters
1
Save from anywhere
Paste a URL or use the browser extension to save articles, threads, and links directly to your library.
2
Automatic parsing & embedding
Content is parsed, cleaned, chunked, and embedded into Pinecone as vector representations — ready for semantic retrieval.
3
Query in plain language
Ask "what did I save about RAG architectures?" or "find articles related to product discovery" — and get precise results from your own library.
4
AI surfaces relevant content
The RAG layer retrieves the most semantically relevant chunks and synthesises an answer with source links back to the original articles.
5
Read in a clean interface
Every saved article is available in a distraction-free reader view. Highlight passages, add notes, and organise with tags.
What it's built with and why
| Technology |
Role & rationale |
| Next.js 16 |
Full-stack framework using the App Router. Server Components keep the UI fast and the data-fetching simple; Route Handlers power the API layer without a separate backend. |
| TypeScript |
End-to-end type safety across the data model, API routes, and UI components — critical when building on top of a relational schema with Prisma. |
| Prisma + PostgreSQL |
Prisma ORM provides a type-safe database client generated from the schema. PostgreSQL stores users, articles, tags, and highlights with full relational integrity. |
| Auth.js |
Authentication with email/password, Google OAuth, and GitHub OAuth — all with a single configuration. Session management and CSRF protection included out of the box. |
| Pinecone |
Vector database for storing article embeddings. Chosen for its managed infrastructure — no self-hosting required, and it scales to millions of vectors without configuration overhead. |
| RAG pipeline |
Articles are chunked and embedded on save. At query time, the top-k relevant chunks are retrieved and passed to an LLM with the user's question to generate a grounded, sourced answer. |
In active development
The core save-and-retrieve loop is functional. Auth, article storage, and the reader
view are working. The RAG layer is integrated and returning relevant results from
personal libraries.
Build a browser extension for one-click saving from any page.
Add a highlights and annotations system — save specific passages, not just full articles.
Introduce a weekly digest: an AI-generated summary of the most relevant things you saved but haven't read.
Explore a public beta — the core experience is strong enough to test with a small group of early users.